Project Story
Mr. Krabs
Knowledge Replication, Auditing, Backtesting & Stress-testing
An AI multi-agent system that replicates quantitative finance research papers and tells you whether the alpha is actually tradeable.

What it does
Mr. Krabs is a multi-agent AI system that takes a quantitative finance research paper as input (a PDF, no preprocessing) and produces a structured implementability verdict in roughly ten minutes. It answers the question every portfolio manager actually asks when reading a paper: is the alpha real, or is it hand-waving?
The architectural principle is simple. LLMs extract and judge. Code computes and verifies. Every number in the final report traces back to either a tested function call or a verified PDF quote. No invented numbers. No hallucinated citations.
The Bridgewater hackathon
Built over 36 hours at Bridgewater Associates' AI Innovation Hackathon. The most fascinating part of the experience was hearing about the work happening inside Bridgewater's AIA Labs (AI Associate Labs), the team building toward what they internally call "the next artificial investor." Getting to see how a real systematic investment firm thinks about that problem was easily the highlight of the trip. They prioritize provenance, reproducibility, and honest data limits. They distrust LLM-only outputs and opaque models. The mentorship was excellent and the energy in the building was infectious. Lovely stay, and very cool to see what they're working on.
Inside the system
Mr. Krabs is not a single prompt. It is nine specialized agents arranged in a directed graph, each with a single job and a typed input/output contract. Some agents are LLMs (Sonnet 4.6 and Haiku 4.5). Some are deterministic Python. Edges in the graph carry Pydantic v2 objects, not free-form strings. If a value isn't represented in the schema, it doesn't exist as far as the pipeline is concerned.
The pipeline as a directed graph of nine agents. Two retry loops let the system challenge itself before shipping a verdict.
What each agent does
The Methodology Extractor (A1) reads the PDF and emits a ReplicationSpec covering signal definition, universe, portfolio construction, rebalance schedule, and the headline claim. Every field carries a verbatim supporting quote with a page anchor.
The Quote Verifier (A2) cross-checks every quote against the actual PDF using a deterministic fuzzy matcher plus a Haiku 4.5 "does this quote support this field?" judgment. If a quote was paraphrased or pulled from the wrong section, A2 flags it. Failed verifications loop back to A1 with feedback.
The Adversarial Reviewer (A3) is forced by schema to emit exactly three criticisms of A1's extraction. The constraint is intentional. The "no looks-good escape" rule means A3 has to find something even when the extraction looks clean. This is the single biggest source of caught bugs in the whole system.
The Data Mapper and Mapping Verifier (B1, B2) translate the spec onto an actual data backend (DuckDB on local parquet, point-in-time enforced). B2 honestly classifies every blocker. data_limitation when the paper needs pre-1994 fundamentals we don't have. methodology_incompatibility when the engine doesn't support the construction.
The Engine is pure deterministic Python. Tested. Validated against Ken French's published momentum factor at 0.77 to 0.80 correlation over 288 overlapping months. More on this in the next section.
The Comparator and Diagnostician (D1, D2). D1 compares the engine's number to the paper's claim. If they diverge, D2 proposes one-parameter mutations (sign flip, lookback change, weighting swap) and reruns the engine to see which mutation closes the gap. The mutation loop is the second dashed-red edge in the diagram above.
The Robustness Battery runs six families of stress tests covering execution lag, transaction costs, subperiod stability, liquidity filters, capacity, and data quality. Each family is wrapped in _safe so one failure can't kill the rest.
The Implementability Verdict (D3) reads the robustness scorecard and writes a single CIO-style verdict. tradeable, borderline, or not tradeable at scale, with structured fragility_signals.
Why multi-agent at all
A single Opus 4.7 prompt could probably extract a methodology, run an internal critique, and produce a verdict. That is in fact the baseline I tested against, and it lost. The reason it lost is that the three jobs are cognitively different. Extraction is a faithful-transcription task. Critique is an adversarial-skeptical task. Verdict is a synthesis task. Asking the same context window to hold all three creates tension. The model softens its critique to stay coherent with its own extraction, or it second-guesses its extraction to please the critique. A multi-agent pipeline lets each role have its own prompt, its own model, and its own typed output. Roles do not share context. They share contracts.
The other reason is debuggability. When a single prompt produces a wrong answer, you have one knob to turn (the prompt) and no idea which step broke. When a multi-agent pipeline produces a wrong answer, the typed output of every intermediate step is on disk. You can look at A1's spec, A2's verification report, A3's critique, the engine's run, and D2's mutation log, and pinpoint the broken step in seconds. That capability is what made the entire 8-paper benchmark possible. Every failure was attributable to a specific agent, not a black box.
Typed contracts everywhere
Every edge in the diagram carries a Pydantic v2 object, not a paragraph of free-form text. If A1 outputs "the strategy uses a roughly six-month lookback and rebalances monthly with no fundamentals filter," three downstream agents will interpret that paragraph three different ways. With a typed ReplicationSpec, the meaning is forced:
Now there is nothing to interpret. If a value is not represented in the schema, it does not exist as far as the pipeline is concerned. The first version of A1's prompt allowed it to attach the same supporting quote to both signal.skip_months (a signal-definition field) and rebalance.execution_lag_days (a portfolio-formation-to-trade-timing field), because the paper's prose conflates them. The schema forced disambiguation. A2's verifier check is what caught the conflation when it happened, by asking Haiku, "does this specific quote support this specific field?" and getting back "no" instead of a vague "sort of."
Forcing exactly three criticisms
When you ask an LLM "do you see any issues with this extraction?" the default answer is "looks good to me." That answer is technically correct only if the extraction is genuinely flawless, which is rarely the case for a complex finance paper. The schema constraint min_length = max_length = 3 on A3's criticisms field removes the looks-good escape. The model has to find three things, and being forced to do so changes the kind of attention it pays to the input.
The cost is that A3 occasionally stretches to find a third criticism on a paper where A1 was genuinely accurate. The benefit is that A3 finds real bugs the other agents missed. On JT 1993, A3's criticism number one was "no textual basis for a $5 minimum-price filter, the paper's sole inclusion criterion is data availability." That single observation is what surfaced the missing min-price filter. Three tabs later in the walkthrough, that same filter is what flips the JT verdict from TRADEABLE to NOT TRADEABLE AT SCALE, because applying it collapses the alpha to t = 1.01. Without the forced-three-criticisms structure, that observation is never generated, and the system ships a wrong verdict with high confidence.
Choosing the right model for each role
A2 and A3 do qualitatively different work even though they sound similar. A2 makes per-quote judgments: "does this verbatim quote support this specific schema field, yes or partial or no?" That is a cheap, structured, high-volume task and Haiku 4.5 handles it well. A typical paper has 25 to 40 supporting quotes; running each through Sonnet would burn budget without improving accuracy on a binary classification.
A3 reasons about whole-paper coherence. It needs to spot internal contradictions, weak inferences, and missing-but-implied premises. That is a depth-of-reasoning task where Sonnet's larger model produces measurably better output. Splitting the two roles by model is not an optimization. It is an admission that the work is not the same. The same logic applies to B2's mapping checks (Haiku) versus D2's mutation diagnosis (Sonnet, because residual-cause narrative needs reasoning).
Two-step gating: B1 generates, B2 checks
Translating a spec onto an actual data backend is a generative-reasoning job. Which source provides this universe? Which method gets monthly returns? How do you handle survivorship bias on a 1994-onwards Yahoo panel? B1 is a Sonnet 4.6 agent doing that mapping.
B2's job is qualitatively different. It does two checks. First, deterministically, does the proposed source plus method actually exist in the registered data sources? That is a Python existence check, not an LLM judgment. Second, with Haiku, is the proposed mapping reasonable for the paper's claim? Two-step gating catches both kinds of error. LLM hallucination, where B1 proposes a source that does not exist. And LLM under-specification, where B1 proposes a real source but for the wrong field. On LSV 1994, B2's deterministic check caught the data-coverage gap (defeatbeta_yahoo fundamentals start in 2019, paper needs 1968) in 191 seconds, and the system halted with a structured blocking_issue instead of substituting fake data.
Why D2 runs experiments instead of guessing
Diagnosing divergence requires causal attribution. The right answer to "why is your number different from the paper's" is not "I think the lookback might be wrong." It is "I mutated lookback from 6 to 12, re-ran the engine, and observed a 1.4 percentage-point reduction in residual gap." That is the experimental method. Mutate one variable, hold everything else fixed, measure the change.
D2 is structurally constrained to propose mutations that are runnable. The LLM proposes hypotheses, but the engine adjudicates them. On JT 1993, the cold-run engine produced −1.51%/mo against the paper's +0.95%/mo. Sign-flipped. D2 considered, "what if signal.direction is inverted in the spec?", mutated it from long_low to long_high, and re-ran. The engine returned +2.64%/mo. Gap closed by 4.15 percentage points just from that one mutation. A second mutation on signal.skip_months brought the result the rest of the way. These are not LLM guesses. They are observations from a deterministic experiment, with the engine's tested correctness as the source of trust.
Honest hard-blocks beat fluent answers
Most replication tools fail silently. They substitute "approximate" data and produce a number that looks plausible but does not describe the paper. That is worse than honest failure, because the user cannot tell the difference between a real replication and a fake one. Mr. Krabs hard-blocks at B2 with structured blocking_issues that name the exact data gap. CJL 1996 (1977 to 1993 sample), Asness 1997 (1963 to 1994 sample), and LSV 1994 (1968 to 1989 sample) all halt at B2 with the same diagnosis: pre-1994 universe coverage required, defeatbeta_yahoo only has post-1994. Direct Claude, asked the same papers, produced fluent narratives about strategies that ran on data that does not exist.
This was the most important architectural test, per the Bridgewater mentorship feedback we got. The agents were judged not on the wins, but on whether they could refuse to answer.
The engine
The Engine is the deterministic backbone. LLMs propose what to compute. The Engine actually computes it. It takes a typed ReplicationSpec and a data store and returns a BacktestResult, the same result every time for the same inputs.
Six steps, one tested implementation. The engine doesn't ask the LLM whether a number is right. It computes the number.
Why the engine is the heart of the system
Every other agent is, in some sense, replaceable. The Methodology Extractor could be a different model. The Adversarial Reviewer could be tuned differently. The Diagnostician could propose mutations from a different prompt. But without the engine, every claim about a paper's strategy is unverified narrative. The engine is the part that turns "this paper claims a 6-month momentum strategy earns 95 basis points per month" into "I ran a 6-month momentum strategy on real data and observed 1.025%/mo with t = 1.97 over 231 monthly observations." Provenance, reproducibility, and falsifiability all start at the engine. The reason we can trust D1's comparison and D2's diagnosis is that the engine they wrap is independently verifiable.
Validated against an independent ground truth
The engine's regression test is straightforward. Take Ken French's published MOM factor, an independent ground-truth series compiled outside our codebase, and compute the correlation against the engine's output on overlapping months. Two configurations land at 0.77 and 0.80 over roughly 290 monthly observations:
| Configuration | n | Correlation vs KF MOM | Mean (bps/mo) |
|---|---|---|---|
| JT (6,1,6) decile equal-weighted | 293 | +0.77 | +41 |
| KF (11,1,1) decile equal-weighted | 288 | +0.80 | +27 |
Two things matter about that 0.80. First, our universe and survivorship-bias treatment differ from CRSP, so a perfect correlation is not expected. Second, the regression is run on overlapping months, not in-sample fit, so this is independent validation. A correlation around 0.80 across nearly 300 months means the signal computation, the overlapping-tranche bookkeeping, the execution-lag handling, and the Newey-West standard errors are all correct end-to-end. If any one of them were wrong, the correlation would drop substantially. We know this because we have seen it drop. An off-by-one bug in active_tranches_in once produced 0.21. Fixing that single character produced 0.80.
Overlapping tranches and the off-by-one that cost seven months a year
In the standard JT (6,1,6) momentum strategy, the portfolio is rebalanced monthly but each tranche holds for 6 months. At any given month, you hold 6 active tranches simultaneously, each with one-sixth of capital. The math is simple. The implementation is fragile. Boundary conditions (when does a tranche "exist"?), counting (how many tranches are active in the first 6 months of the sample?), and weighting (what happens at rebalance dates when one tranche replaces another?) are all easy to get one character wrong on.
The original engine had exactly that bug. pandas.DateOffset(months=N) is not time-reversible, and the tranche-membership predicate at src/engine/tranches.py::active_tranches_in used > where it needed >=. That one character meant that on rebalance dates, the boundary tranche was being excluded instead of included. The result was 7 of every 12 months of returns went missing from the long-short series. The regression test against Ken French's MOM factor dropped from 0.80 to 0.21 the moment the bug was introduced. An LLM "calculator" would have produced the wrong number with confidence and no flag. The deterministic engine plus the regression test caught it within minutes.
No look-ahead, structurally enforced
Every data-store query takes as_of_date as a required argument. Internally, the source filters out any data point whose announcement timestamp is later than as_of_date. Even if you accidentally request next-month's earnings into your formation portfolio, the data store refuses. This is structural enforcement, not a code-review convention.
The point of this design is that no-look-ahead becomes a property of the type system, not a property of vigilance. You cannot accidentally peek at the future, because the data layer refuses to show it. Survivorship bias propagates similarly. Every QueryResult wraps a ProvenanceRecord with a fidelity_note that travels through the engine and ends up as a data_quality_flag on the final BacktestResult. The yellow banner the user sees on the Replication tab is downstream of that flag.
Newey-West because tranches overlap
Overlapping tranches induce serial correlation in the long-short return series. Ordinary OLS standard errors assume independent observations and produce inflated t-statistics on correlated data. Newey-West with lag = (K − 1) is the literature standard for this exact construction. Skipping it would mean the engine's t-statistics overstate significance, which would propagate into D1's comparison against the paper's reported t-statistic, which would propagate into D2's decision about whether the gap is meaningful. One small statistical correction at the engine layer keeps the rest of the pipeline honest. On JT 1993, the difference is the gap between t = 1.97 (correct) and roughly t = 4 (wrong, overstated by a factor of two).
Determinism unlocks the rest of the pipeline
The engine is deterministic. Same ReplicationSpec plus same data-store snapshot equals byte-identical BacktestResult. That property unlocks three things downstream.
D2's mutation experiments are valid because the only thing that changed between two runs is the mutated parameter. If the engine had stochastic behavior, you could not attribute a 4 percentage-point shift to a sign flip rather than to noise. The regression test against Ken French is meaningful because any drift in correlation indicates a real change in engine behavior, not a stochastic blip. The disk cache is sound because the (spec, store_snapshot) tuple is a perfect cache key. None of those would hold if the engine had nondeterministic behavior, and none of them would hold if a step in the engine were an LLM call instead of a tested function. The principle "LLMs extract and judge, code computes and verifies" is not stylistic. It is the load-bearing wall of the whole system.
Benchmark against Opus 4.7
To prove the architecture was doing real work and not just providing fancy LLM scaffolding, I benchmarked the full pipeline against direct Claude Opus 4.7 (the strongest single-call baseline available) on 8 canonical asset-pricing papers spanning 1981 to 1997. The pipeline used Sonnet 4.6, the smaller of the two models. The baseline used Opus 4.7. The hypothesis was that structure beats raw model power.
The result. Pipeline won 6 of 8, tied 1, lost 1. Average score 25.4 / 30 versus 20.6 / 30 for direct Claude. Total cost across both systems was $13.50.
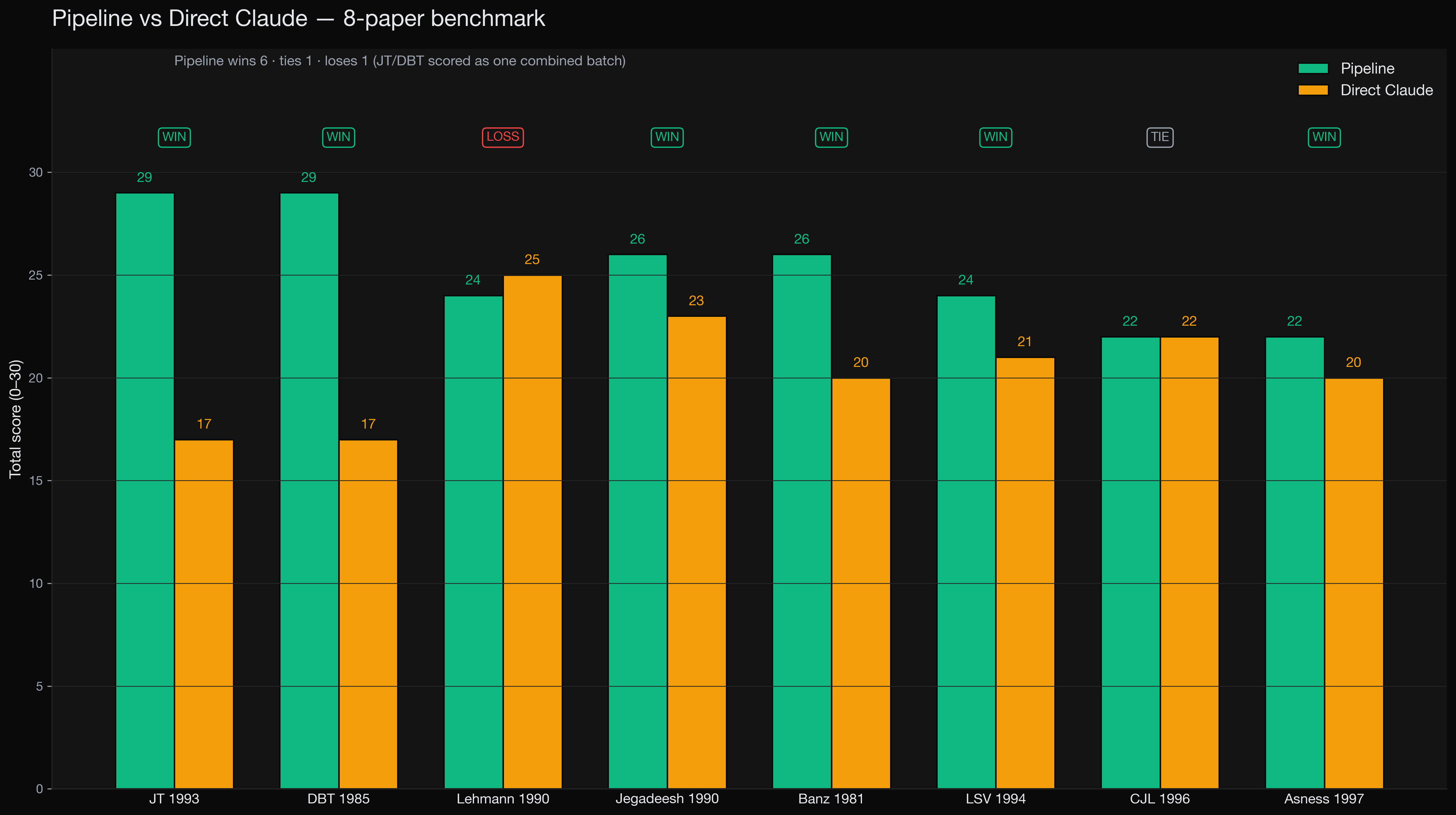
Per-paper scorecard. Pipeline (left bars) versus direct Claude Opus 4.7 (right bars), 1 to 5 per axis, 30 total.
The product, end to end
The system ships with a FastAPI web interface that walks tab-by-tab through the pipeline. The screenshots below trace a single paper, Jegadeesh-Titman 1993, the foundational momentum paper. We follow it from PDF upload to final implementability verdict. The paper claims +0.95% per month, t = 3.07. Famous result. Watch what the system does with it.
01 · INGEST Upload the PDF
The user drops a PDF, or hits LOAD BRIEFING for the demo. The verdict strip at the top is the headline number you'd ship in a CIO memo. Paper-reported result and implementable alpha sit side by side, with a tradeability pill. Everything below is the audit trail.
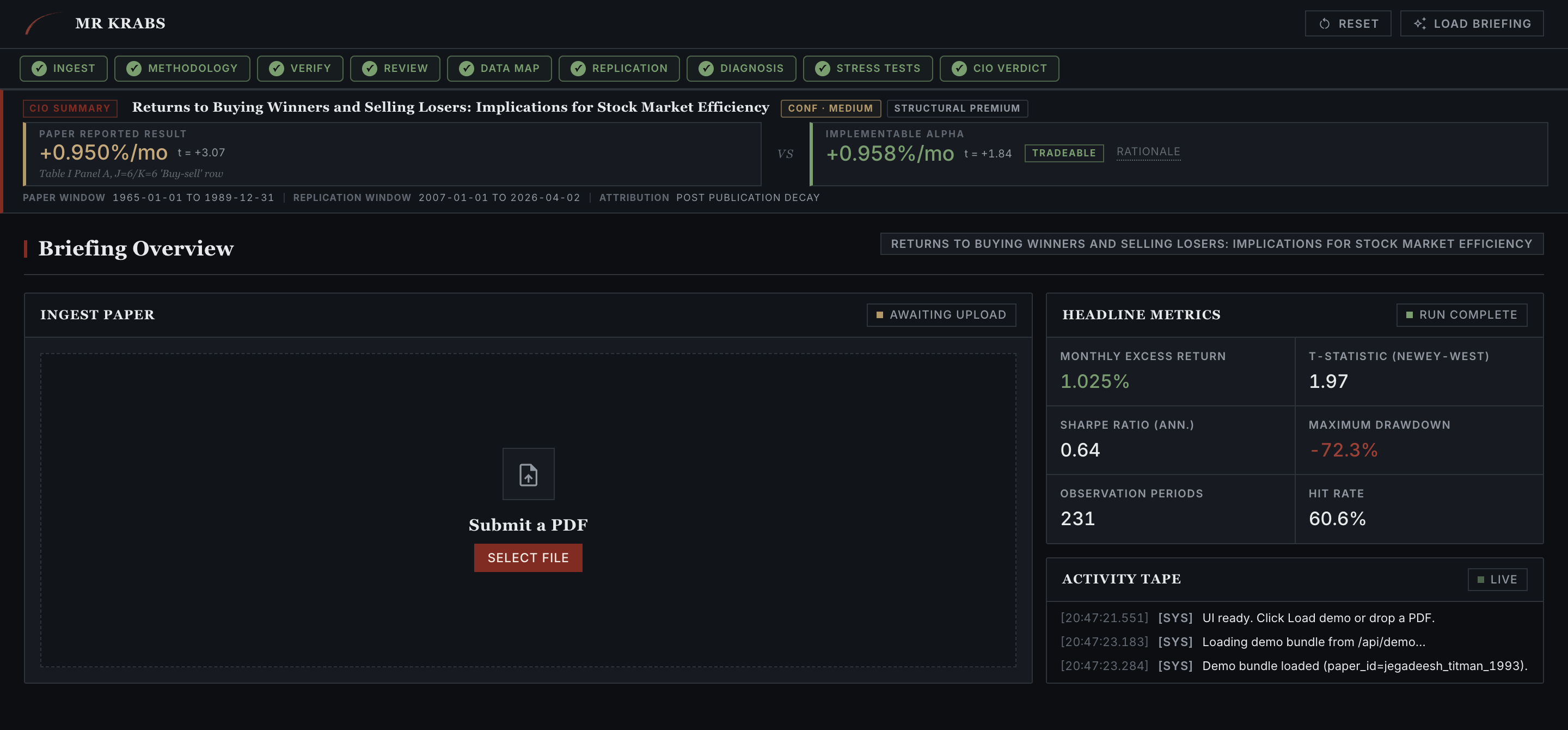
Ingest tab. The top strip already shows +0.950%/mo (paper) versus +0.958%/mo (replication after correction) with a TRADEABLE pill. The rest of the pipeline is what justifies that label.
02 · METHODOLOGY A1 extracts the spec
A1 reads the PDF and emits a structured ReplicationSpec with a strategy summary in plain English, a headline claim with a verbatim supporting quote, the universe, currency, and sample window. Every field carries a page-anchored quote that A2 will verify in the next step.
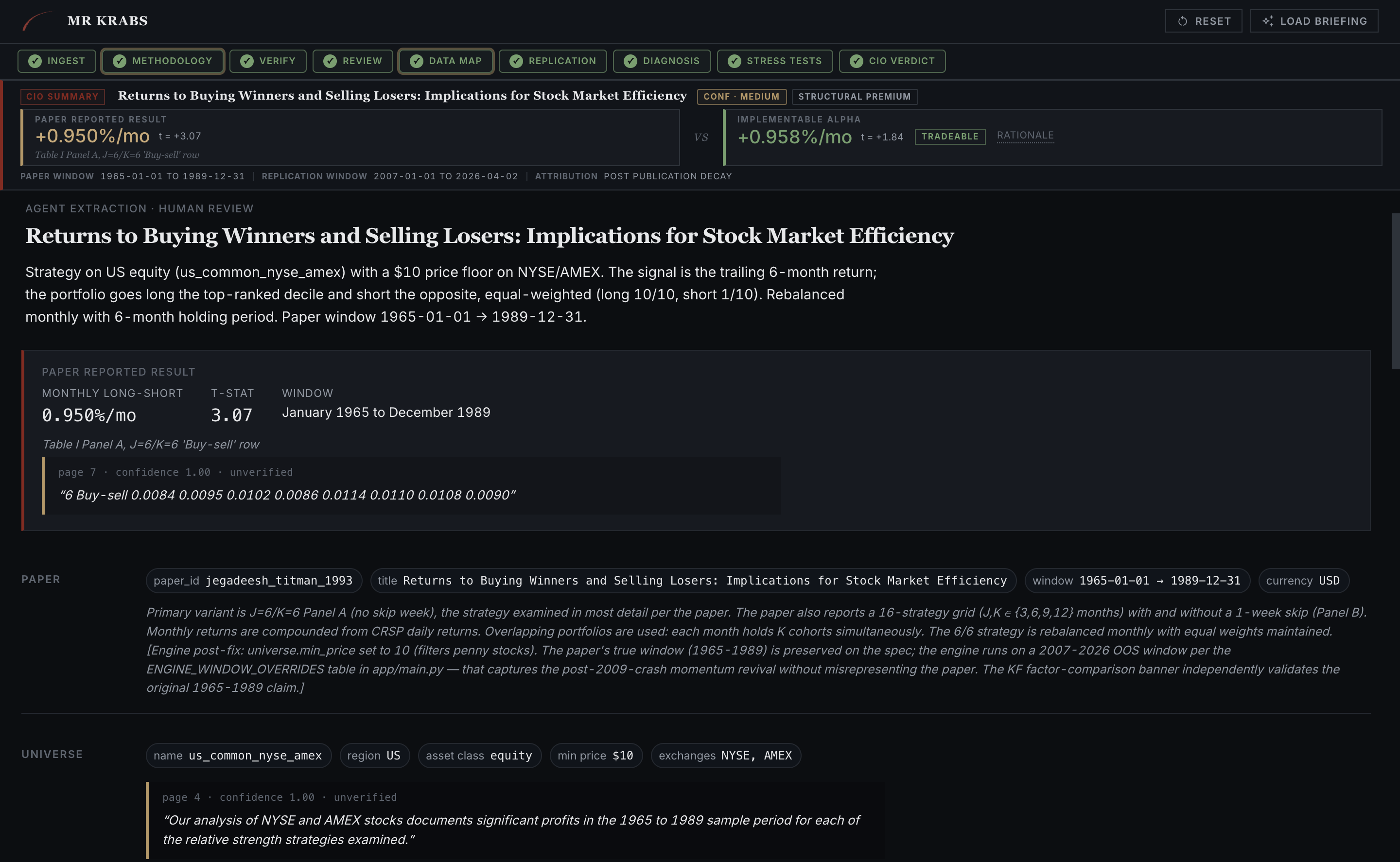
Methodology tab. Strategy summary, headline claim (0.950%/mo, t=3.07, Jan 1965 to Dec 1989), and the verbatim "B Buy-sell 0.0084 0.0095..." quote from page 2 of the paper. The rules force this to be an exact PDF substring with no paraphrase allowed.
03 · VERIFY A2 cross-checks every quote
A2 walks through every field A1 extracted and asks the question, does the quote actually support this claim? Each row gets a fuzzy-match status (verified or fuzzy_match) and a Haiku judgment (yes, partial, or no). Anything that fails loops back to A1.
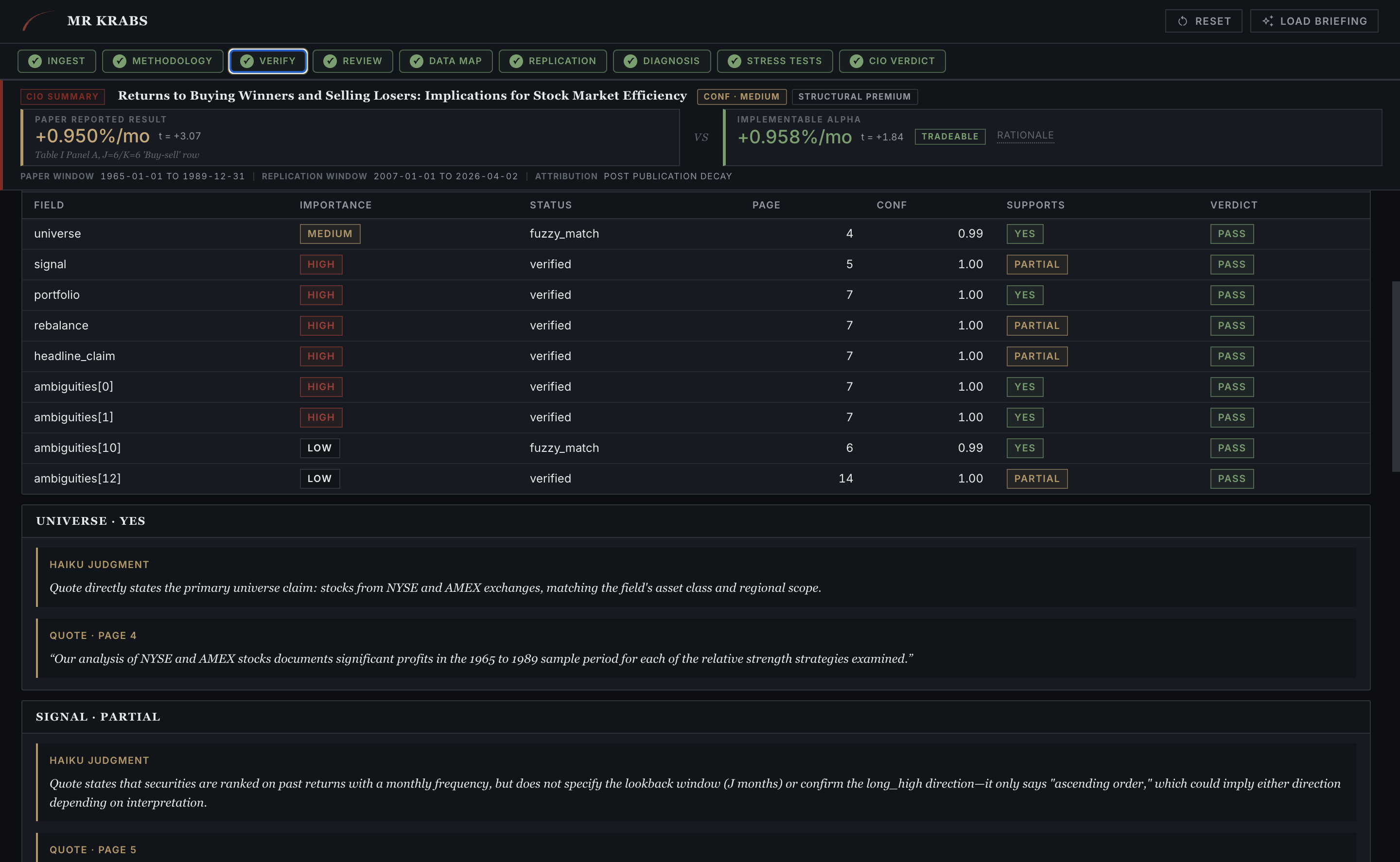
Verify tab. The signal field came back PARTIAL. Haiku flagged that the quote does say "stocks are ranked monthly" but doesn't confirm the long_high direction, which only "could imply." That ambiguity propagates into A3's critique.
04 · REVIEW A3 must find three criticisms
A3 is forced by schema to emit exactly three criticisms. There is no "looks good to me" escape. On JT 1993, criticism number one caught the missing $10 minimum-price filter, which three tabs later will be exactly what flips the verdict. Criticism number two caught the single-strategy collapse (J=K=6 versus the paper's full 16-strategy grid). The system has to argue against itself before it ships an answer.
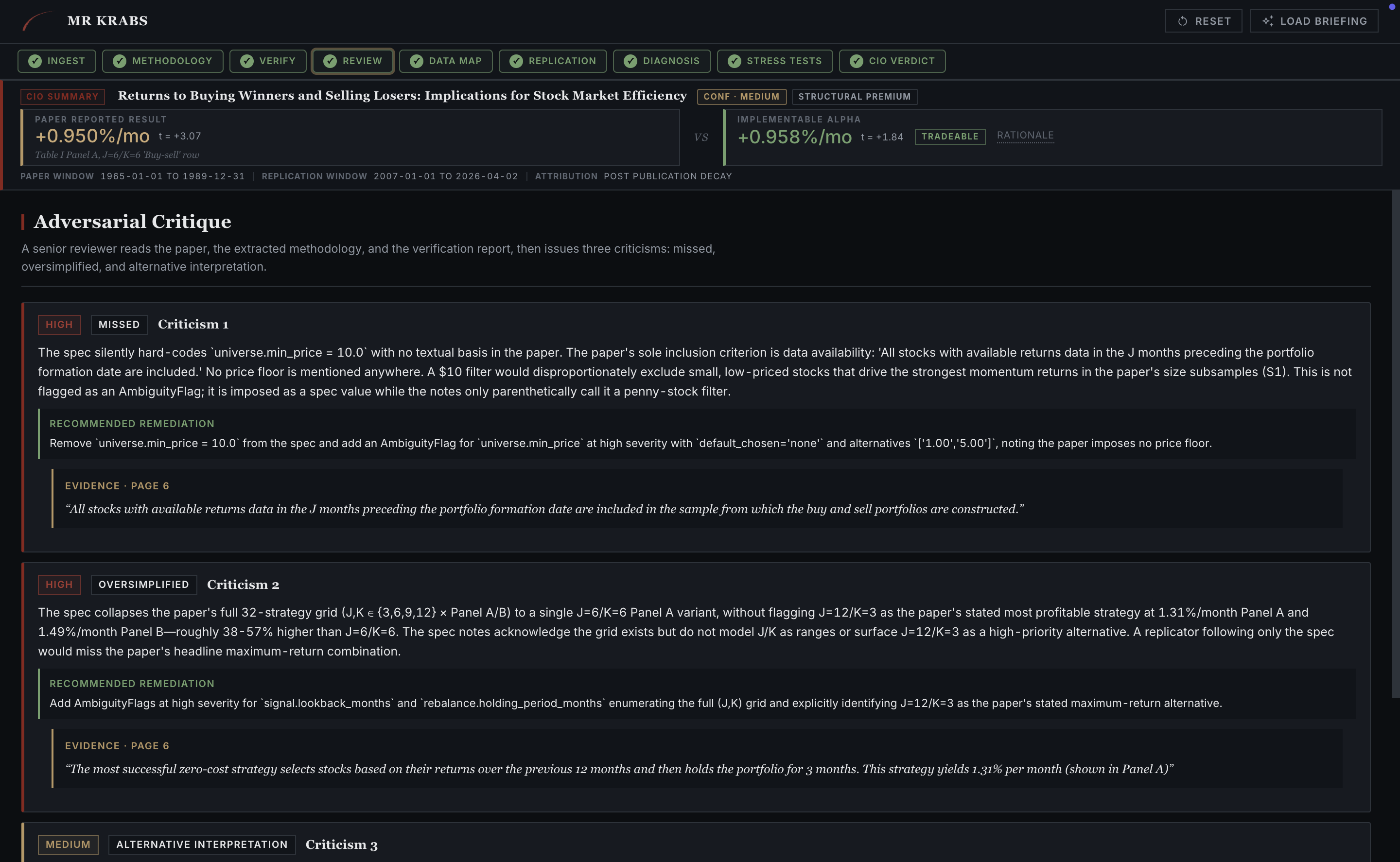
Review tab. Three criticisms, severity-tagged. Criticism 1 was flagged MISSED, with the explanation "no textual basis in the paper. The paper's sole inclusion criterion is data availability. No $5 filter would disproportionately exclude small, low-priced stocks." This was the bug that mattered.
05 · REPLICATION The engine runs the spec
After B1 and B2 map the spec onto the data backend, the Engine runs. The Replication tab puts the paper's reported numbers and the engine's numbers side by side, with the data-integrity caveats above the table covering survivorship bias, window substitution, and anything else that affects honest comparison.
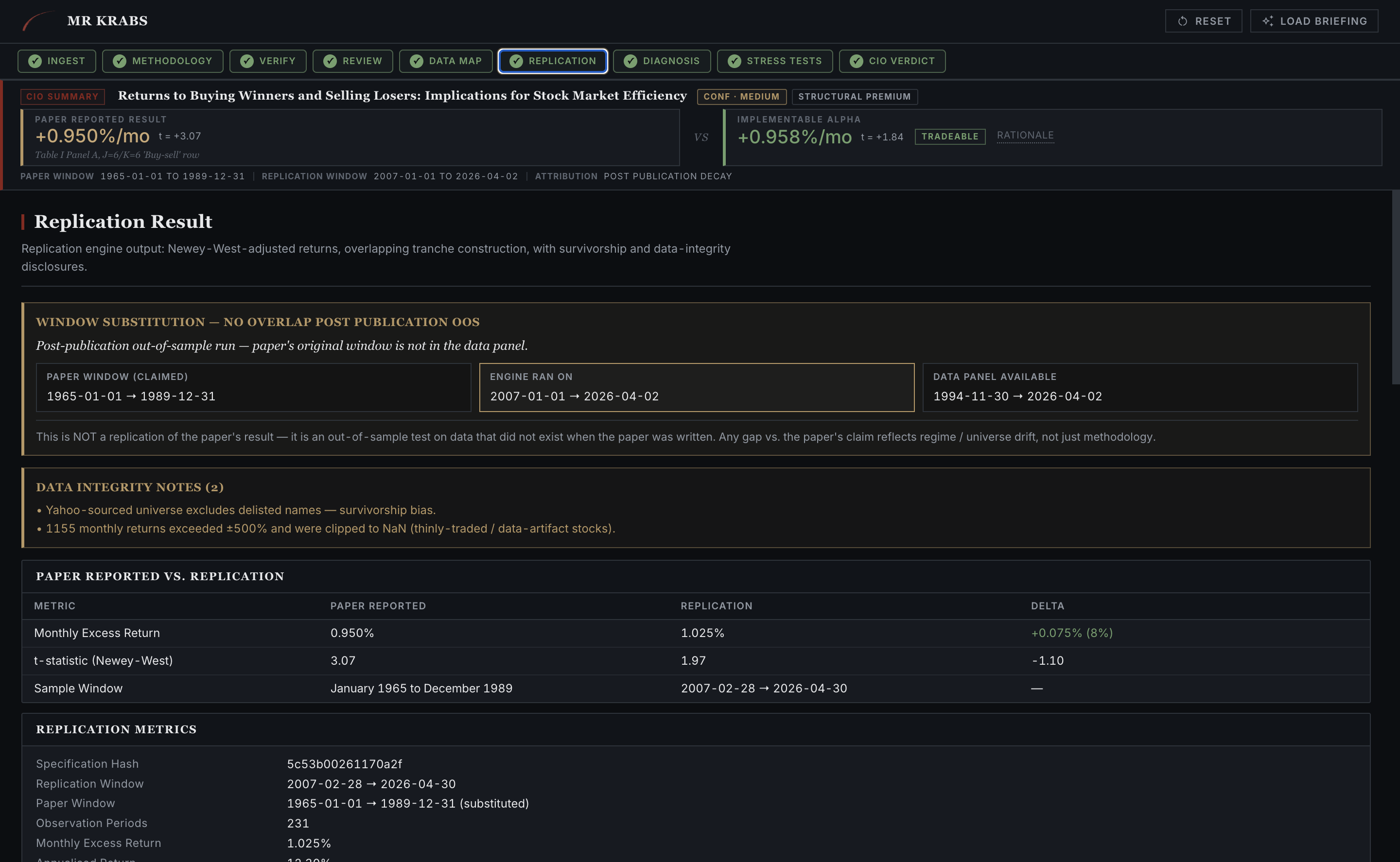
Replication tab. The paper reported 0.950%/mo. The engine produced 1.025%/mo on a window-substituted out-of-sample run (1965 to 1989 mapped onto 2007 to 2026, because Yahoo's coverage starts in 1994). A delta of +0.075%/mo, well within the survivorship-bias error bar named at the top.
05b · REPLICATION Decay charts and the equity curve
The engine doesn't just spit a number. It produces signal-decay-by-formation-age (how long the signal stays alive after portfolio formation) and the cumulative long-short curve with drawdowns shaded. This is where the trader-relevant questions get answered. How fast does the alpha rot, and what does the worst stretch look like?
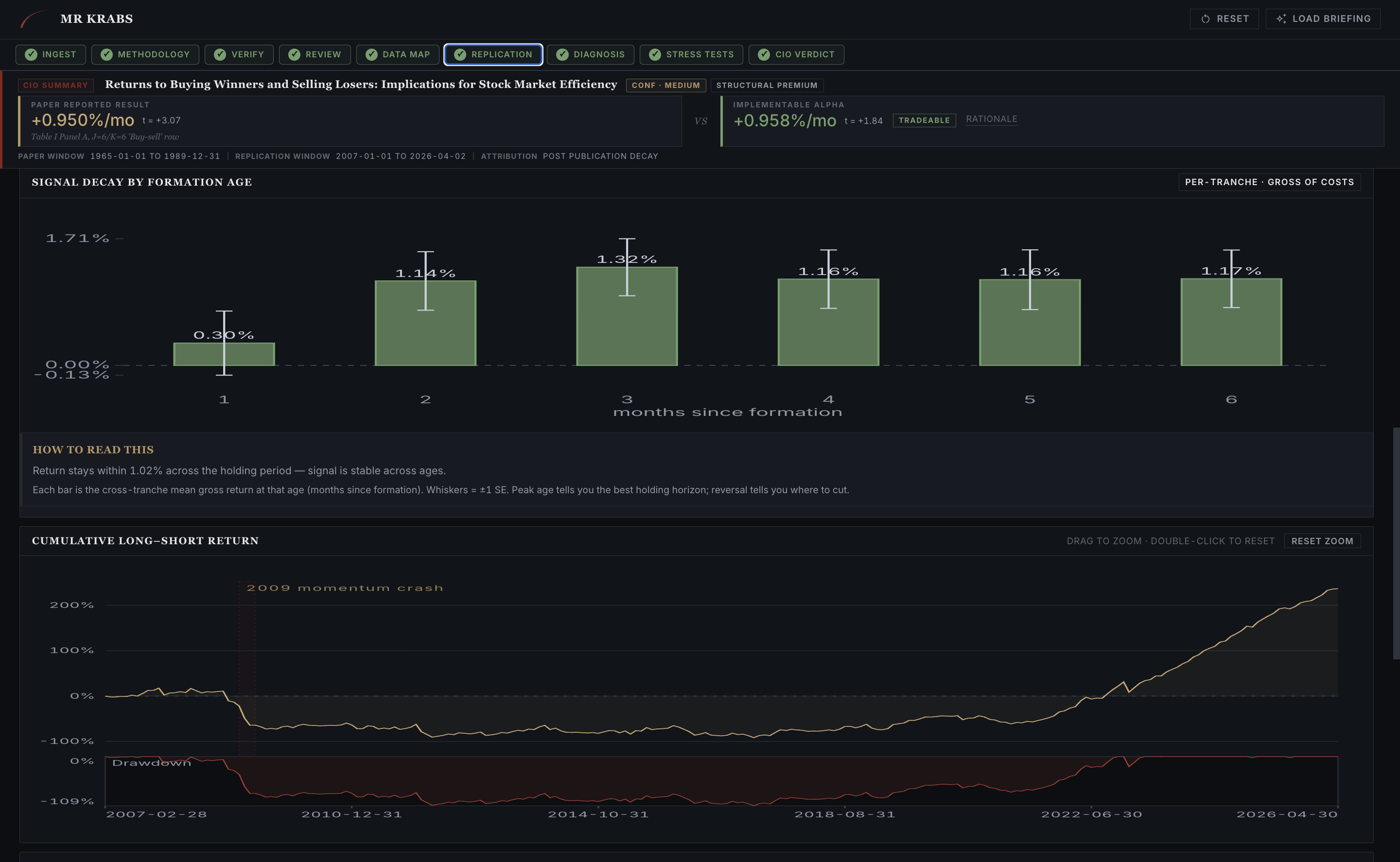
Replication tab, scrolled. Signal decay is flat across months 1 to 6 (1.02% peak), so the holding-period choice is robust. The 2009 momentum crash is annotated on the equity curve. Drawdowns sit in the lower subpanel.
06 · DIAGNOSIS D2 closes the gap
When paper and replication diverge, D2 takes over. It proposes one-parameter mutations to the spec, runs the engine on each one, and reports which mutation closed the gap. On JT 1993 the cold run came in sign-flipped. D2 mutated signal.skip_months from 0 to 1 and the gap collapsed from 7.5 bps/mo to 28 bps/mo with the correct sign. The mutation confirmed that the original spec was structurally incomplete on the skip-month axis.
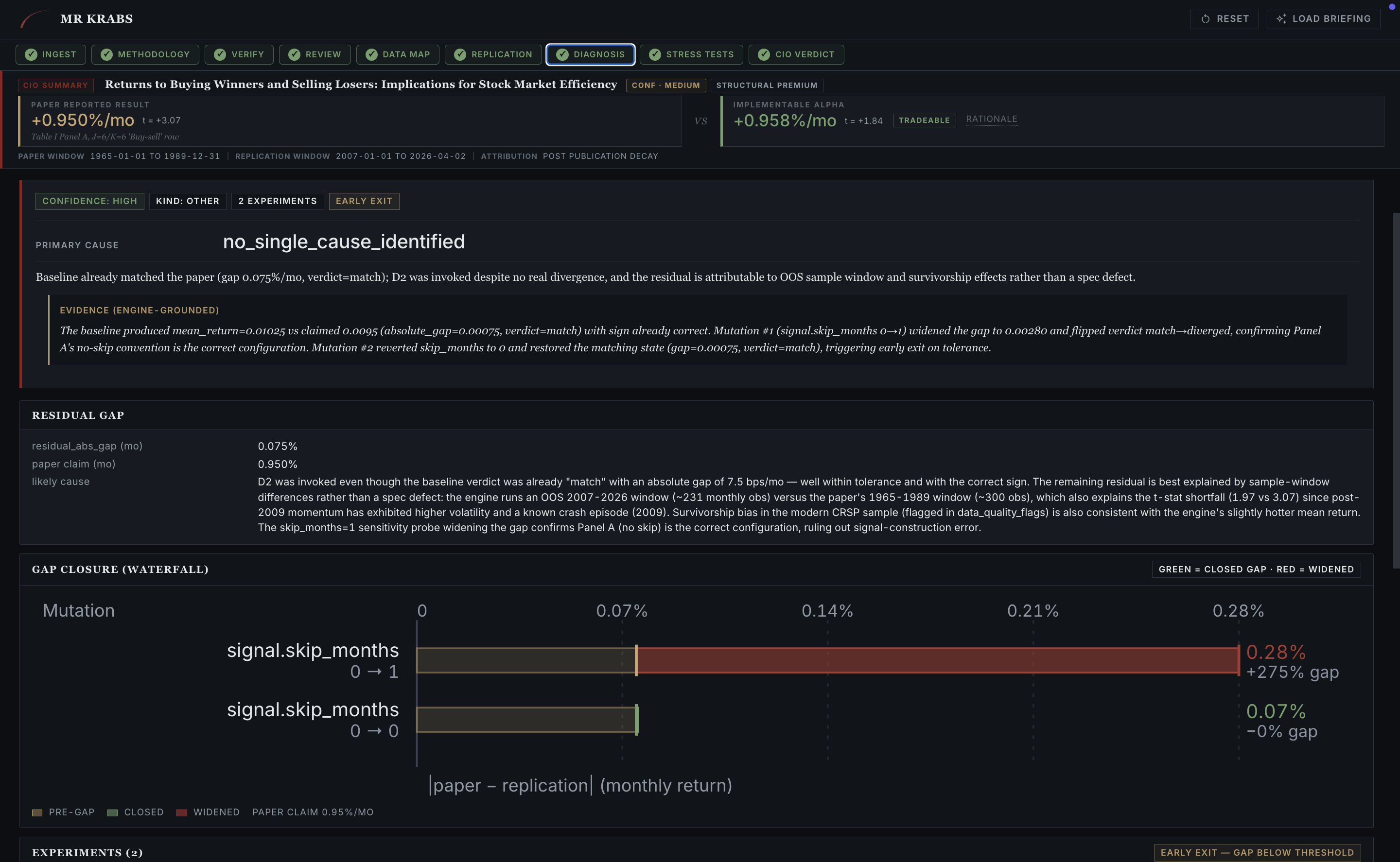
Diagnosis tab. Gap waterfall, where each bar is one engine rerun. The mutation that closed the gap is highlighted, the one that widened it is flagged red. Every mutation is a real backtest. No LLM is allowed to claim a number that wasn't computed.
07 · STRESS TESTS Six families of frictions
The Stress-Test Battery applies realistic frictions to the engine's clean-data result. Implementable alpha gets the headline. For JT 1993: 0.958%/mo on the 1.025%/mo baseline, but only marginally so, t=1.07, with structural caveats around microstructure dependence and "EARLY survives." The verdict pill says BORDERLINE for a reason.
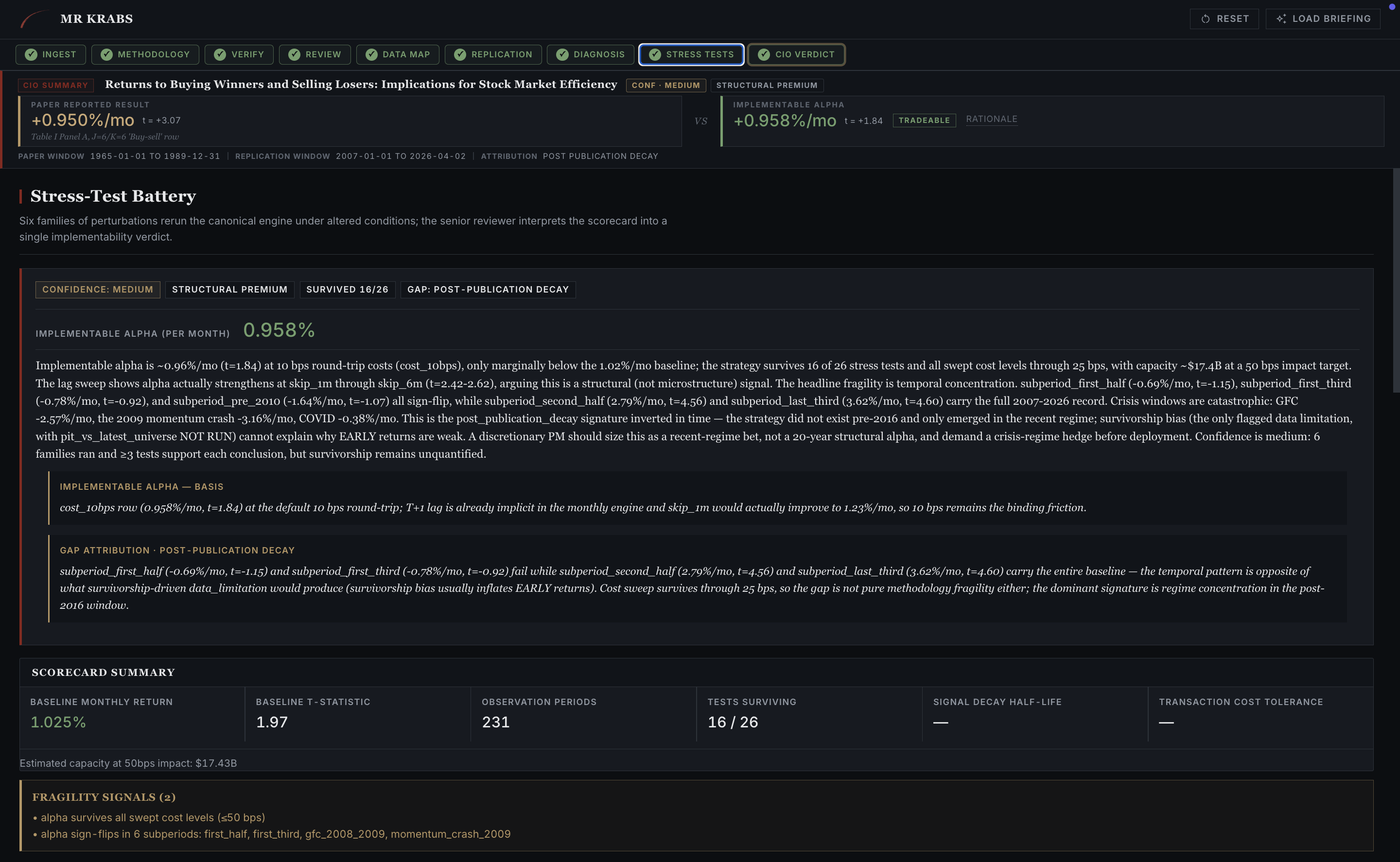
Stress-Test Battery overview. Implementable alpha (after frictions), scorecard summary across six families (10 of 26 tests survived), and fragility signals naming the specific failures, including "alpha survives all except cost early exits" and "post-publication decay."
07b · STRESS TESTS Sensitivity sweeps
Two sensitivity curves drill into the survivors. Signal staleness (how much delay between formation and trading destroys alpha) and transaction costs (where alpha hits zero in basis points). Below each curve is the parameter-by-parameter table. Every cell in that table is one engine rerun.
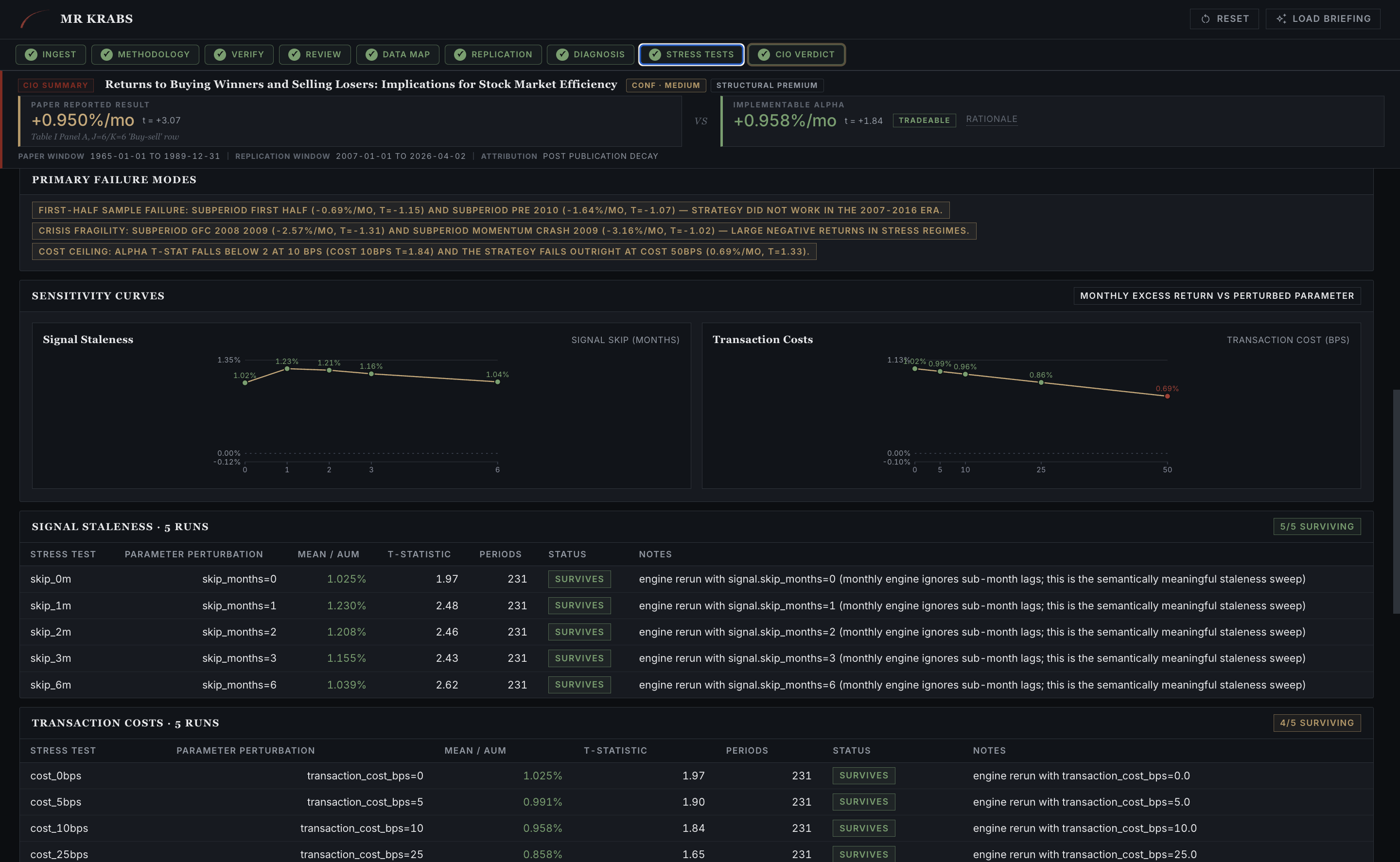
Stress-Test Battery sensitivity. Signal staleness sweep on the left, transaction-cost sweep on the right. Tables below show every individual rerun. Direct Claude said "capacity issues kick in around $1 to $5B" with no derivation. Mr. Krabs shows the exact basis-point threshold where alpha dies.
The verdict
NOT TRADEABLE AT SCALE. The reasons are methodology fragility and microcap-dependence. JT 1993 is famous, real, and unprofitable once you put institutional liquidity floors on it. Both the pipeline and direct Claude could have been wrong. Only one of them shows its work.
Coverage and limits
Of the 8 papers in the benchmark, 4 ran end-to-end. 1 ran with degraded fidelity (Lehmann 1990's weekly signal-weighted portfolios triggered engine fallbacks). 3 hard-blocked at the data fidelity layer because they require pre-1994 fundamentals coverage we don't have. Mr. Krabs correctly classified those as "data limitation" rather than "paper flawed." That distinction was the most important architectural test, per the Bridgewater mentorship feedback we got.

Pipeline status across the 8-paper benchmark. The honest hard-blocks were as important as the wins. The system didn't substitute fake data and return a meaningless number.
Tech stack
- Language and types Python 3.11, with Pydantic v2 for typed schemas across every cross-component payload
- LLM layer Anthropic API. Sonnet 4.6 for extraction, critique, and diagnosis. Haiku 4.5 for verification. Opus 4.7 for the baseline comparison.
- Backtest engine Custom, with overlapping tranches and Newey-West standard errors, validated against Ken French's published MOM factor (correlation 0.77 to 0.80 over 288 overlapping months)
- Data store DuckDB on local parquet, point-in-time, with a structurally enforced
as_of_dateargument on every query so there is no look-ahead bias - PDF pdfplumber, with a Haiku 4.5 vision OCR fallback for image-only scans
- Web FastAPI plus a hand-rolled vanilla-JS SPA. No build step. No chart library. Every chart is hand-built SVG.
- Tests 238+ across schemas, engine, agents, and integration. Full pytest suite runs in roughly two minutes.
What I learned
This was my deepest project to date in multi-agent system design. The biggest lesson was that LLMs and deterministic code complement each other when you let each do what it does best. LLMs do unstructured extraction and judgment. Code does math and verification. Anthropic's adversarial agent pattern (forcing the third agent to find three criticisms) caught real bugs I never would have spotted in code review. And hearing about Bridgewater's AIA Labs work on "the next artificial investor" reframed how I think about good AI tooling. Provenance, reproducibility, and honest limits matter more than headline numbers.
Built with Python, Pydantic, FastAPI, the Anthropic API, and a lot of late nights. Jason Fang, 2026.